Gramática
Una gramática, en el contexto de los lenguajes de programación, es la estructura ubicada en la fase de análisis sintáctico que determina el correcto orden en el que deben estar los tokens generados por el analizador léxico. La estructura de la gramática está compuesta por componentes terminales (Tokens) y componentes no terminales (Cada uno definido como una producción), así pues si a una gramática le agregamos acciones (que pueden interactuar con los atributos de los componentes) transformamos una gramática en una traducción dirigida por la sintaxis. El corazón de nuestro intérprete será la gramática, encargada de reconocer la entrada, generar el AST, y controlar los posibles errores que existan en la entrada. Para generar la gramática utilizaremos la herramienta JavaCC.
JavaCC
JavaCC es el acronimo para Java Compiler Compiler, que puede interpretarse como compilador de compiladores, es una herramienta que nos permite analizar un archivo de especificación del lenguaje fuente y producto de ese análisis obtener un conjunto de clases (archivos .java) que realizarán el parseo de una entrada de caracteres, pasando por las fases de análisis léxico y análisis sintáctico.
Dicho de una forma más simple, JavaCC construye analizadores descendentes recursivos. Los archivos de especificación de lenguajes (que típicamente son asociados con la extensión .jj) cuentan con varias secciones, la primera de ellas es la sección en donde le indicamos a JavaCC aspectos propios del comportamiento de nuestro parser (que distinga entre mayúsculas y minúsculas, que reconozca caracteres UNICODE, la habilitación del debug del parser, la cantidad de tokens de anticipación, etc), en este enlace se encuenta un detallado listado de todas las opciones disponibles para utilizar en esta sección, para nuestro caso utilizaremos unicamente dos valores distintos a los que trae JavaCC por defecto.
options {
// El parser no distinguirá entre mayúsculas y minúsculas
// para los tokens, por ejemplo para las palabras reservadas
IGNORE_CASE = true;
// El parser será totalmente dinámico, sin esta opción la
// cadena de entrada se podría analizar una única vez
STATIC = false;
}
La siguiente sección es donde empieza a aparecer el verdadero código en Java, esta sección es la definición de la clase encargada del parseo de la entrada; delimitada por PARSER_BEGIN(id) y PARSER_END(id), donde id es el nombre que llevará la clase prinicipal y el prefijo que servirá para otras clases que utiliza el analizador. Dentro de esta sección se declara el paquete al que pertencerán todas las clases generadas por JavaCC, además de todos los imports necesarios para que las acciones que agreguemos más adelante funcionen correctamente; también pueden definirse variables o métodos globales que estarán disponibles en cualquiera de nuestras producciones.
PARSER_BEGIN(ParserSBScript)
//Definición del paquete
package org.esvux.sbscript.parser;
//Imports necesarios
import ···
PARSER_END(ParserSBScript)
El orden de las secciones es importante unicamente para las dos primeras secciones; luego de ellas puede venir en, cualquier orden, la especificación de las producciones o la especificación de los tokens (fase de análisis léxico). En la sección de definición de tokens se utilizan expresiones regulares comunes y corrientes, asociadas a un nombre en específico, esta sección inicia con TOKEN: y dentro de un juego de llaves { ··· } se definen los tokens que formarán nuestro lenguaje. A continuación se encuentran varias de las definiciones típicas de cualquier lenguaje escritas para JavaCC.
TOKEN:{
// Un símbolo cualquiera
< PYC : ";" >
// Una palabra reservada
| < PR_PRINCIPAL : "Principal" >
// Un número entero o con punto decimal
| < NUMERO : (["0"-"9"])+ | (["0"-"9"])+ "." (["0"-"9"])+ >
// Un identificador
| < ID : ["a"-"z","A"-"Z"] (["a"-"z","A"-"Z","0"-"9","_"])*>
// ··· así hasta definir todos los tokens de nuestro lenguaje
}
Como se puede observar cada token está delimitado por los símbolos < y >, dentro de estos símbolos se define el nombre (regularmente en mayúsculas, aunque sin ser obligatorio) seguido de : y luego la expresión regular, cada token está separado uno de otro por un símbolo | (típico OR), como parte del análisis léxico también se pueden utilizar otras instrucciones para definir, por ejemplo, los caracteres que ignorará el parser o tokens especiales, como los comentarios.
La Gramática
Configurado el comportamiento del parser y definidas las expresiones regulares de cada token, ahora es tiempo de declarar cada una de las producciones, para efectos de esto JavaCC tiene una gran ventaja sobre otros analizadores, la forma en que se declaran las producciones brinda facilidad para el uso de atributos y también para la construcción del cuerpo de las producciones, mezclando metacaracteres de las expresiones regulares y caracteres propios de la notación BNF.
Cada producción se define de manera similar a como se define un método en Java, se escribe el tipo de la producción, su identificador, los parámetros con los que contará, un primer juego de llaves para declarar variables con valores iniciales y un segundo juego de llaves que es donde se definirá el contenido. El contenido o cuerpo de la producción se define colocando los no terminales como llamadas a métodos ID() y utilizando los símbolos <ID> para hacer referencia a los terminales, además de birndar la posibilidad de colocar cualquier sucesión de caracteres sin ser especificada en las reglas léxicas por medio del uso de las comillas dobles "".
// Producción de ejemplo, reconoce la declaración de variables
void DEC_GLOBAL():{ /* Variables locales y/o valores iniciales */ }
{
TIPO_VAR() <ID> ( "," <ID> )* [ "=" EXP() ] <PYC>
}
En notación BNF la producción anterior sería algo como DEC_GLOBAL ::= TIPO_VAR L_ID ASIGN ";" en donde TIPO_VAR, como en el ejemplo, sería la producción que reconoce un tipo de todo el listado de tipos disponibles para una variable; difiriendo con el ejemplo se deben agregar las producciones adicionales L_ID, que reconoce una lista de identificadores, como lo hace JavaCC con el comodín * y ASIGN que representaría la opcionalidad del valor asignado, que JavaCC reemplaza con los comodines [ ].
Dentro del cuerpo de cada producción se puede interactuar con los valores de cada componente, tanto terminales como no terminales. Para acceder al valor de los terminales se deben declarar (en la sección de las primeras llaves de cada método) tantas variables de tipo Token como elementos terminales se desee acceder sin interferir entre ellos, para luego utilizar el caracter = y acceder al token que cada terminal representa. Así mismo se puede acceder a los valores de los no terminales declarando variables locales del tipo que corresponda a cada no terminal en su definición y utilizando el símbolo = de la misma forma para asignar el valor a la variable que corresponde.
// Acceder a los valores de los componentes
void DEC_GLOBAL():{ Token id; Token aux; String tipo; }
{
tipo=TIPO_VAR() id=<ID> ( "," extra=<ID> )* [ "=" EXP() ] <PYC>
}
Al terminar de reconocer el ";" del final se tendría a disposición los valores del token ID, la cadena que representa el tipo de las variables (asumiendo que la producción TIPO_VAR regresa un String); pero te preguntarás ¿qué hago con los valores que ya obtuve? pues para poder utilizar esos valores, JavaCC brinda la posibilidad de insertar acciones como código java en cualquier parte del cuerpo de la producción, agregando un juego de llaves { } dentro de las cuales se puede colocar cualquier sentencia de código java que utilice los valores disponibles al gusto del programador.
// Incorporación de acciones
void DEC_GLOBAL():{ Token id; Token aux; String tipo; }
{
tipo=TIPO_VAR() id=<ID>
{ System.out.println(tipo + " : " + id.image); }
(
"," extra=<ID>
{ System.out.println(extra + " : " + id.image); }
)*
[
"=" EXP()
{ System.out.println("Variables con valor asignado..."); }
]
<PYC>
}
Pero qué serían las traducciones dirigidas por la sintaxis sin la posibilidad de utilizar atributos, para saber cómo funcionan los atributos en JavaCC existe la siguiente sección en donde se expone una forma práctica de implementar atributos heredados en JavaCC, sin dejar de lado los atributos sintetizados.
Los Atributos
Si ya has llevado alguna vez el curso de Compi2, sabrás que en las traducciones dirigidas por la sintaxis existen dos tipos de atributos, los sintetizados y los heredados, cuál utilizar, cuál es la diferencia entre ellos, para tener la mejor respuesta posible consultá el capítulo 5 del libro de texto del curso; de forma muy superficial lo que necesitas saber es que la diferencia entre estos tipos de atributos es la forma en que se definen sus valores, los atributos sintetizados -en azul- definen sus valores a partir de sus nodos hijos (hijos en el árbol de análisis sintáctico). Mientras que los atributos heredados -en rojo- definen sus valores a partir de la información de los nodos que, dentro del árbol de análisis sintáctico, son sus hermanos o su padre directamente.
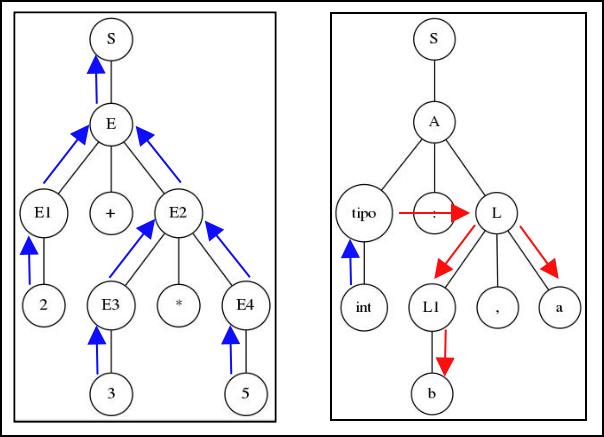
De esta manera, podemos decir que los atributos sintetizados son representados por el return de cada producción, así pues si en la declaración de una producción esta se define de tipo Nodo, al final de su cuerpo es necesario que se retorne un objeto de tipo Nodo, estaríamos entonces sintetizando un objeto de tipo Nodo.
// Ejemplo de atributo sintetizado
String TIPO_VAR():{ Token tok; String tipo; }
{
(
tok=
{ tipo = tok.image; }
|
tok=
{ tipo = tok.image; }
|
tok=
{ tipo = tok.image; }
)
// Sintetizando el tipo...
{ return tipo; }
}
La estrategia de JavaCC para implementar atributos heredados es definir los atributos heredados como parámetros en la o las producciones en donde son necesarios; por ejemplo, asumiendo que se desea realizar una declaración de variables con esta producción DECLARA ::= TIPO_VAR L_ID, la acción deseada, como en uno de los ejemplos anteriores, es imprimir el tipo y el identificador de cada variable, para esto se obtendrá el tipo y se heredará a la producción L_ID para que pueda ser utilizado en dicha producción.
// Ejemplo de atributo heredado
void DECLARA():{ String tipo; }
{
// Se envía el atributo obtenido de TIPO_VAR
// (hermano de L_ID) como atributo heredado
tipo=TIPO_VAR() L_ID(tipo)
}
// Declaración del atributo heredado
void L_ID(String tipo):{ Token tok; }
{
tok=<ID>
{ System.out.println(tipo + " : " + tok.image); }
(
"," tok=<ID>
{ System.out.println(tipo + " : " + tok.image); }
)*
}
Durante el desarrollo de proyectos grandes, como los proyectos de Compi2, es muy útil dejar al mínimo necesario el código que va en las producciones, para eso existen diferentes patrones de diseño de software entre los que están singleton y factory.